Revisiting Evaluation of Knowledge Base Completion Models
Pouya Pezeshkpour, Yifan Tian, Sameer Singh
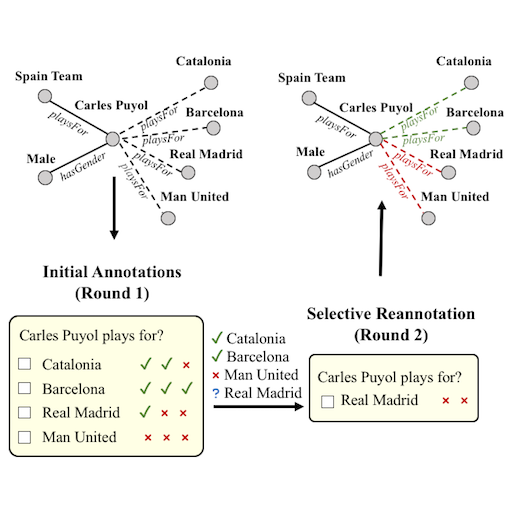
Keywords: Knowledge Graph Completion, Link prediction, Calibration, Triple Classification
TLDR: We study the shortcomings of link prediction evaluation and provide a new task based on triple classification
Abstract:
Representing knowledge graphs (KGs) by learning embeddings for entities and relations has led to accurate models for existing KG completion benchmarks. However, due to the open-world assumption of existing KGs, evaluation of KG completion uses ranking metrics and triple classification with negative samples, and is thus unable to directly assess models on the goals of the task: completion. In this paper, we first study the shortcomings of these evaluation metrics. Specifically, we demonstrate that these metrics (1) are unreliable for estimating how calibrated the models are, (2) make strong assumptions that are often violated, and 3) do not sufficiently, and consistently, differentiate embedding methods from each other, or from simpler approaches. To address these issues, we gather a semi-complete KG referred as YAGO3-TC, using a random subgraph from the test and validation data of YAGO3-10, which enables us to compute accurate triple classification accuracy on this data. Conducting thorough experiments on existing models, we provide new insights and directions for the KG completion research. Along with the dataset and the open source implementation of the models, we also provide a leaderboard for knowledge graph completion that consists of a hidden, and growing, test set, available at https://pouyapez.github.io/yago3-tc/.